Cet article explique comment calculer à quel point deux textes sont différents. Il ne s'agit bien évidemment pas de déterminer si deux textes sont égaux, mais d'obtenir un nombre exprimant la différence qui existe entre deux chaînes de caractères.
À la suite de chacun des articles de ce site, vous avez sans doute remarqué des suggestions concernant des articles qui pourraient vous intéresser. Le générateur de ce site utilise un algorithme de recherche des articles ayant un contenu similaire. Puis, il les classe en fonction du niveau de proximité avec le texte en cours de lecture. Bien sûr, il ne s'agit que d'une approximation et dans le cas d'un article concernant un sujet encore inédit sur votre site, l'algorithme aura un peu de mal à faire un rapprochement, mais c'est déjà mieux que rien et cela incite le visiteur à consulter d'autres contenus.
Il existe plusieurs solutions techniques pour évaluer la distance entre deux chaînes de caractères. Nous examinerons la distance de Levenshtein ainsi que l'algorithme simhash de Charikar. Dans les deux cas, gardez à l'esprit qu'il s'agit d'une estimation mathématique et pas d'une analyse qui impliquerait de comprendre le sens du texte.
Par exemple, on peut classer les phrases suivantes par ordre de similarité sémantique (comprendre 1 est plus proche de 2 que de 3) :
Cependant, mathématiquement l'ordre est plutôt le suivant (comprendre 1 est plus proche de 2 que de 3) :
Et c'est bien là la faiblesse de l'approche. Il existe des algorithmes d'analyse et de comparaison sémantique comme LSI, mais ils seraient également bien en peine si on les employait avec mon exemple, car il faut un texte beaucoup plus long pour une analyse statistique efficace.
Dans les deux cas, il faut préparer le contenu à analyser. Comme notre exemple concerne des documents HTML, il faut en extraire le texte seulement. Des expressions régulières comme celle reproduite ci-dessous seront donc utiles (selon le contenu, on pourrait aussi nettoyer les motifs <script>*</script> et <style>*</style>). Note : ces deux lignes de code sont à placer à l'extérieur des fonctions de manière à ce que les expressions régulières ne soient compilées qu'une seule fois et pas à chaque fois qu'elles seront utilisées.
remTags = regexp.MustCompile(`<[^>]*>`)
oneSpace = regexp.MustCompile(`\s{2,}`)
La distance de Levenshtein permet de mesurer mathématiquement la similarité entre deux chaînes de caractères. Elle est égale au nombre minimal de caractères qu'il faut supprimer, insérer ou remplacer pour passer d’une chaîne à l’autre. C'est cet algorithme qui est utilisé par la bibliothèque d'autocomplétion dont je vous parlais dans un article précédent.
Le problème de cette méthode est qu'il faut comparer chaque article à tous les autres.
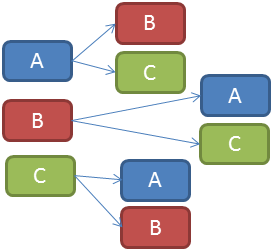
Calcul des distances de Levenshtein
Avec ce schéma, on comprend que si le site possède n articles, alors il faudra calculer n * (n - 1) distances de Levenshtein entre les articles du site. Même en appliquant les méthodes d'optimisation expliquées par la suite, j'obtiens sur un ordinateur récent (i5-2500K) une durée moyenne de calcul de 110 ms pour un article de 500 mots.
Voici un exemple de code optimisé par rapport à d'autres implémentations trouvées sur le net. L'occasion de faire quelques remarques concernant le comportement des programmes go et de citer quelques techniques d'optimisation. Si vous comparez ce code avec celui de la bibliothèque gocleo (vous pouvez également consulter l'extrait de code complet sur le Playground qui compare et mesure les différentes implémentations), vous remarquerez les différences suivantes :
Attention au fait que ces techniques sont liées à mon cas d'usage. Il ne faut pas les considérer comme de bonnes pratiques à généraliser sans réfléchir. Il se peut même qu'elles ne vous apportent rien dans un autre cas de figure.
func LevenshteinDistance5(a, b *string) int {
la := len(*a)
lb := len(*b)
d := make([]int, la + 1)
var lastdiag, olddiag, temp int
for i := 1; i <= la; i++ {
d[i] = i
}
for i := 1; i <= lb; i++ {
d[0] = i
lastdiag = i - 1
for j := 1; j <= la; j++ {
olddiag = d[j]
min := d[j] + 1
if (d[j - 1] + 1) < min {
min = d[j - 1] + 1
}
if ( (*a)[j - 1] == (*b)[i - 1] ) {
temp = 0
} else {
temp = 1
}
if (lastdiag + temp) < min {
min = lastdiag + temp
}
d[j] = min
lastdiag = olddiag
}
}
return d[la]
}
Je vous conseille la lecture de mon article sur l'auto-complétion. Et les liens externes suivants :
L'idée générale de l'algorithme est de découper un texte en features (dans notre cas, une feature sera un mot). Puis de calculer un hash représentatif du texte. Autrement dit, un hash calculé en fonction des features qui le composent. Ce hash (un entier non signé de 64 bits) est calculé une seule fois et cela prend moins d'une milliseconde pour un texte de 500 mots.
Pour comparer deux textes, il suffit alors de calculer la distance de Hamming qui sépare les deux hash. On obtient un entier non signé de 8 bits à l'issue du calcul. La durée de ce calcul se mesure en nanosecondes.
Prenons l'exemple d'un site de 1000 articles de 500 mots. Comme il n'est plus nécessaire de comparer un à un les articles, on passe d'un temps de calcul moyen de 30 heures (1000 * 999 * 0,11 / 602) à quelques secondes.
En plus de la bibliothèque simhash, il nous faudra une bibliothèque du sous-dépôt officiel go.text permettant de normaliser le texte à traiter (nous en parlerons dans un autre article).
go get github.com/mfonda/simhash go get code.google.com/p/go.text/unicode/norm
Sans entrer dans les détails, on commence par composer une chaîne de caractères en minuscules et normalisée en substituant les symboles Unicode visuellement équivalents (avec norm.NFKC). Chaîne de caractères que l'on passe à la fonction Simhash qui calculera un hash représentatif du texte :
hash1 := simhash.Simhash(simhash.NewUnicodeWordFeatureSet(texte1, norm.NFKC)) hash2 := simhash.Simhash(simhash.NewUnicodeWordFeatureSet(texte1, norm.NFKC))
La fonction Compare calcule la distance de Hamming entre les deux hash que nous venons de construire :
simhash.Compare(hash1, hash2)
J'ai créé le projet gorelated sur Github qui permet de vous faire une idée de la vitesse d'exécution et de la pertinence des résultats dans plusieurs langues. Il s'agit d'un programme écrit en go qui analyse les fichiers HTML contenus dans un répertoire et fournit la liste, pour chacun des fichiers, des documents au contenu similaire.

Retrouvez mes cooordonées

Une traduction du blog officiel de golang expliquant le mécanisme de la réflexion en Go. Lire »
Traduction d'un article du blog officiel expliquant comment échanger des données entre deux programmes golang grâce à un format natif Lire »
Préconisations officielles pour la gestion des erreurs dans un programme golang. Cet article complète les explications sur panic, defer et recover Lire »
Traduction d'une partie des spécifications officielles du langage go, cet article explique comment go gère la mémoire. Lire »
Traduction d'une partie des spécifications officielles du langage Go, cet article explique comment développer en Go. Lire »
Soyez le premier à commenter cet article
Tous les commentaires sont soumis à modération. Les balises HTML sont pour la plupart autorisées. Les liens contextuels et intéressants sont en follow.
